All Categories
Featured
Table of Contents
Amazon now typically asks interviewees to code in an online paper file. This can differ; it might be on a physical white boards or a digital one. Check with your employer what it will be and exercise it a great deal. Since you understand what concerns to expect, allow's concentrate on exactly how to prepare.
Below is our four-step prep plan for Amazon data researcher candidates. Prior to investing 10s of hours preparing for a meeting at Amazon, you should take some time to make certain it's actually the best company for you.

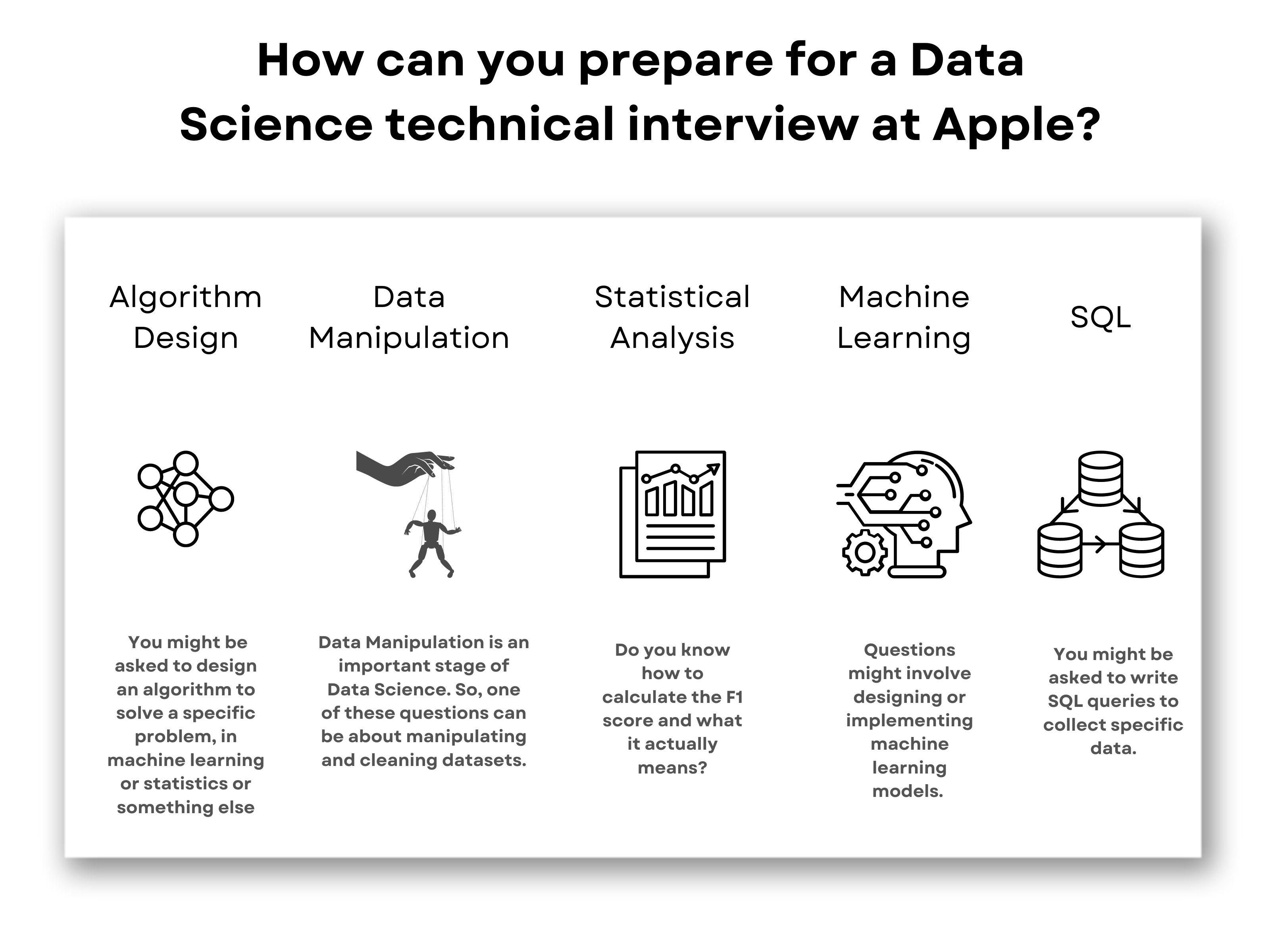
Exercise the approach making use of example inquiries such as those in section 2.1, or those about coding-heavy Amazon placements (e.g. Amazon software application development designer interview guide). Technique SQL and programs inquiries with medium and tough degree examples on LeetCode, HackerRank, or StrataScratch. Take a look at Amazon's technical subjects page, which, although it's designed around software program development, must provide you an idea of what they're looking out for.
Keep in mind that in the onsite rounds you'll likely have to code on a white boards without being able to implement it, so practice composing via problems on paper. Uses cost-free courses around initial and intermediate equipment discovering, as well as information cleaning, data visualization, SQL, and others.
Real-life Projects For Data Science Interview Prep
You can publish your very own concerns and go over subjects likely to come up in your interview on Reddit's data and artificial intelligence threads. For behavioral interview inquiries, we suggest finding out our step-by-step approach for responding to behavioral concerns. You can then make use of that technique to practice responding to the instance concerns offered in Section 3.3 over. Make sure you have at the very least one story or instance for each of the principles, from a wide variety of placements and jobs. A great way to exercise all of these different kinds of inquiries is to interview yourself out loud. This may appear weird, yet it will dramatically improve the method you connect your solutions during an interview.
Trust us, it functions. Practicing on your own will just take you until now. One of the main difficulties of data researcher meetings at Amazon is communicating your different answers in such a way that's easy to understand. Consequently, we strongly recommend experimenting a peer interviewing you. Preferably, a great area to start is to exercise with close friends.
Be advised, as you might come up against the adhering to problems It's hard to understand if the comments you obtain is accurate. They're not likely to have expert knowledge of interviews at your target company. On peer platforms, people often lose your time by disappointing up. For these reasons, several candidates skip peer mock interviews and go right to mock interviews with an expert.
Using Big Data In Data Science Interview Solutions

That's an ROI of 100x!.
Information Scientific research is quite a huge and varied field. As an outcome, it is really difficult to be a jack of all trades. Traditionally, Information Science would concentrate on mathematics, computer technology and domain expertise. While I will briefly cover some computer scientific research principles, the bulk of this blog site will primarily cover the mathematical fundamentals one could either require to review (and even take an entire course).
While I understand many of you reviewing this are more mathematics heavy by nature, recognize the bulk of data scientific research (attempt I claim 80%+) is accumulating, cleaning and processing data into a useful type. Python and R are the most prominent ones in the Information Scientific research area. I have actually additionally come throughout C/C++, Java and Scala.
How To Prepare For Coding Interview

It is usual to see the bulk of the information researchers being in one of 2 camps: Mathematicians and Data Source Architects. If you are the second one, the blog will not assist you much (YOU ARE ALREADY REMARKABLE!).
This may either be gathering sensing unit data, parsing web sites or accomplishing studies. After collecting the information, it requires to be transformed into a usable form (e.g. key-value store in JSON Lines data). When the information is collected and placed in a useful format, it is important to carry out some data top quality checks.
Top Challenges For Data Science Beginners In Interviews
In cases of scams, it is extremely typical to have hefty course imbalance (e.g. only 2% of the dataset is real fraud). Such details is necessary to choose the suitable choices for function engineering, modelling and version assessment. For more information, inspect my blog on Scams Discovery Under Extreme Course Inequality.
In bivariate evaluation, each attribute is compared to various other functions in the dataset. Scatter matrices enable us to discover covert patterns such as- features that ought to be crafted with each other- attributes that may need to be gotten rid of to stay clear of multicolinearityMulticollinearity is actually a problem for multiple designs like straight regression and for this reason needs to be taken care of as necessary.
In this section, we will certainly check out some common function engineering techniques. Sometimes, the function on its own may not provide useful details. Picture using net usage data. You will have YouTube users going as high as Giga Bytes while Facebook Carrier customers utilize a number of Huge Bytes.
An additional concern is the usage of categorical worths. While specific values are usual in the information science world, recognize computers can just comprehend numbers.
Creating A Strategy For Data Science Interview Prep
At times, having also many thin dimensions will certainly hamper the performance of the version. A formula generally made use of for dimensionality reduction is Principal Elements Evaluation or PCA.
The usual groups and their below categories are explained in this section. Filter techniques are usually made use of as a preprocessing action.
Common approaches under this group are Pearson's Relationship, Linear Discriminant Evaluation, ANOVA and Chi-Square. In wrapper methods, we attempt to make use of a part of attributes and educate a version utilizing them. Based on the reasonings that we attract from the previous version, we determine to add or remove features from your subset.
Key Skills For Data Science Roles
These approaches are typically computationally extremely expensive. Usual approaches under this classification are Forward Choice, Backward Removal and Recursive Attribute Elimination. Installed techniques combine the top qualities' of filter and wrapper approaches. It's executed by formulas that have their own integrated attribute selection techniques. LASSO and RIDGE are usual ones. The regularizations are given up the formulas listed below as referral: Lasso: Ridge: That being said, it is to recognize the auto mechanics behind LASSO and RIDGE for meetings.
Supervised Discovering is when the tags are readily available. Without supervision Understanding is when the tags are inaccessible. Obtain it? Monitor the tags! Word play here intended. That being stated,!!! This mistake is enough for the recruiter to cancel the interview. One more noob error individuals make is not normalizing the features before running the model.
Direct and Logistic Regression are the most basic and generally used Machine Discovering formulas out there. Before doing any type of evaluation One common meeting slip individuals make is beginning their evaluation with a much more intricate version like Neural Network. Criteria are essential.
{kind=link}
Latest Posts
The Ultimate Roadmap To Crack Faang Coding Interviews
Test Engineering Interview Masterclass – Key Topics & Strategies
Best Free Github Repositories For Coding Interview Prep